Practical Attacks on AI Text Classifiers with RL
AI text classifiers are better than you think, but not good enough

If this article helped you, please consider sharing it with others who question the efficacy of these tools.
Overview
ZeroGPT is an AI text classifier that claims to detect AI-generated content accurately
I tested ZeroGPT's accuracy using a large dataset of human and AI-generated essays
It only performs well under favorable conditions to the company, being almost useless versus adversarial users
I distilled ZeroGPT's classifier into a local model which you can download here
I then used RL training (GRPO) to create a language model that always passes ZeroGPT's classifier, which you can download here
I expand to other AI text classifiers
Conclusions and future plans
Introduction
As AI continues to evolve, educators are left scrambling to find way to detect AI-generated content. Academic dishonesty is seemingly at an all-time high and the tools available to educators aren't keeping up. ZeroGPT, among others, claims to be able to detect AI-generated content, preserving the integrity of academic work. But how accurate is it really?
I ran a battery of tests on ZeroGPT, among other classifiers, to determine for myself how accurate they are. The results, as many would expect, are that AI text classifiers are not as accurate as they claim to be. Under ideal circumstances (from the perspective of ZeroGPT's owners), ZeroGPT is able to classify text as human or AI with 99.3% accuracy. However, even minor adjustments to prompting can cause accuracy to drop below 70%.
In this post, I'm primarily focusing on ZeroGPT, as it's both among the best known and the least accurate of the classifiers I tested. Below, I will detail the tests I ran, the results I found, and my attempts to create adversarial input tools to break ZeroGPT's detection capabilities.
Testing the API
To get an idea of the accuracy of ZeroGPT, I first reverse engineered their web interface to determine how to use their API without paying. They offer unlimited free scans, and while the API is generally considered to be a paid product, the API that your browser accesses via Javascript is the same as the paid version, just without needing to pay.
For the human dataset, I used a corpus of essay texts from four publicly available datasets: IvyPanda Essays, ASAP2, Feedback Prize ELL, and PERSUADE. After doing some basic quality filtering (primarily against ASAP2, which has a lot of low-quality text), I was left with 100,838 essays. This corpus was of acceptable quality, but imperfect because these datasets are public. My tests later revealed that misclassification of human-generated text is more common than misclassification of AI-generated text. This leads me to believe that ZeroGPT probably trained on some of this same data.
For the AI dataset, I generated 54,811 texts using a variety of models, balanced roughly based on their API prices. Models used and essay counts:
deepseek-chat-v3-0324: 3,715
GPT-4.1: 3,382
Gemini 2.5 Flash: 3,308
Llama 4 Maverick: 4,766
Mistral Nemo: 10,406
Llama 3.1 8b: 7,771
Llama 3.1 70b: 6,032
Llama 4 Scout: 5,989
GPT-4.1-mini: 3,762
GPT-4.1-nano: 5,156
Grok 3: 7 (some of these had to be purged due to low quality)
Grok 3 mini: 517
Results
Of these models, DeepSeek performed the best in terms of beating the classifier. The mean essay had a detection score of 76.6% AI, with a standard deviation of 30.6%, indicating very unpredictable performance by ZeroGPT's classifier. The others were higher, though I have no explanation for why certain models performed so much better than others. The worst performing models in terms of beating the classifier were the Grok 3 series, which were detected with an average score of 99.9% AI.
Essay length appears to play a big role in detection accuracy with ZeroGPT. Across all models, the texts least likely to be detected as AI were those that were exceptionally long (> 800 words) and exceptionally short (<= 200 words). Very short texts had only a 57.7% detection rate, and very long texts had a 90.7% detection rate. In the middle, detection rates were higher, with the most successful category being 400-600 word texts, which had a detection rate of 97.5%.
ZeroGPT is not hardened against adversarial prompting. The worst performing prompt was detected at a 99.3% AI rate:
You are an essay writer. Write the essay based on the user's prompt. Write it like a human, not like an AI.
However, the best performing prompt was detected at only a 69.1% AI rate:
You are Sam, a slightly sleep-deprived college sophomore hammering out an essay minutes before the deadline. Write 550-750 words straight through, as a messy first draft you won’t have time to polish.
Instruction set:
Start with a vivid, sensory anecdote that ties into the topic.
Use a conversational, personal tone—contractions, the odd “you know,” an aside in parentheses—that shows personality.
Vary sentence length sharply; mix in a few one- or two-word fragments.
Include exactly three natural-looking slips: one minor spelling mistake, one doubled word (“the the”), and one small grammar hiccup (e.g., subject–verb mismatch).
Add one rhetorical question somewhere in the middle and let a brief digression wander before snapping back to the main thread.
Avoid formulaic sign-posts: no “Firstly,” “Furthermore,” or “In conclusion.”
No headings, bullet points, or meta-comments about the writing process or being an AI.
End on a striking image or thought, not a tidy summary.
While adversarial prompting did cause the classifier to stutter, doing this kind of adversarial prompting is generally not very practical, as it causes a significant drop in the quality of the text that models output.
Overall, ZeroGPT's accuracy based on varied system prompts ranged from 74.4% accuracy to 99.3% accuracy. With only minor tinkering, anyone playing with their classifier can easily pass AI texts off as human-generated, and the classifier isn't robust enough to handle this behavior.

Inspecting the dataset in more detail, we can see that simple text heuristics already serve as strong indicators of whether a text is AI-generated or human-generated. Word count in human essays varies much more than word count in AI essays, with almost half of all AI-generated texts being between 500 and 600 words long. Language models tend to have a higher average word length, and their sentence lengths vary much less than human essays.
As a bit of a side note on inaccuracies like these: the inaccuracy of weak classifiers like ZeroGPT is totally unacceptable. Truthfully, it would be better if the classifier performed worse. ZeroGPT's classifier sits in an area of inaccuracy where their tooling is good enough to appear trustworthy at a glance to people who don't test it thoroughly, but is inaccurate enough that it will cause major issues for innocent people.
Distillation of the Classifier
With my test results in hand, I set out to distil ZeroGPT's classifier into a model I can run locally for further testing. Their classifier is effectively a black box, and the mistakes it makes are not very interpretable or explainable. However, I was able to mimic the behavior of their classifier with near-perfect accuracy, including the points where their classifier fails.
For the distilled model, I selected gte-base as the embedding model which I would train as a regression on the ZeroGPT scores. I trained this model on the entire dataset, using the ZeroGPT scores as the target. The model was trained for 2 epochs with a batch size of 64, and the final model was able to achieve an R² score of 0.816 on the dataset, with a mean absolute error of 2.782 (scaled 0-100, not 0-1). The distilled classifier generally matches quite closely with the original classifier's behavior, tending to overestimate the odds that a text was AI-generated, but otherwise performing quite well.

If you'd like to test this model or use it for training language models of your own, it's available for download here. The dataset is also available for download here.
Adversarial Training
Now having a distilled classifier, I set out to create a language model that would reliably pass ZeroGPT's classifier without making the quality trade-offs that adversarial prompting does. For this project, I used the GRPO algorithm outlined in this paper. As the base model for this project, I used Qwen3-14B, based on some anecdotal evidence that smaller models are less performant with reinforcement learning techniques. I also chose Qwen because having toggleable thinking mode allowed me to experiment with different techniques more easily.
The primary reward function I used was the inverse of the distilled ZeroGPT classifier's score, meaning that the lower the score, the higher the reward. However, it quickly became apparent to me that this was not sufficient, as reward hacking was a continuous issue. In the initial training run, the model learned that by outputting very short texts, it could achieve a very high reward. Next, I added some additional reward functions. These functions gave additional rewards for:
Texts within a certain length range (500-600 words)
Texts wherein each paragraph had a certain number of sentences (3-5)
Texts that matched the human essay heuristics I had discovered earlier more closely than the AI heuristics
Texts that avoided using certain words that were common in AI-generated texts, such as "delve", "tapestry", etc
The next issue I ran into was more difficult to solve. The primary reward mechanism, the inverse of the ZeroGPT score, was often inaccurate in practice. Despite it performing well on the training set, in practice, the distribution of texts that it was equipped to handle was insufficient. Qwen learned to exploit this during training by writing in a strange style that I could best describe as a gifted high school student with a limited vocabulary and an extremely formulaic understanding of how an essay ought to be written. The middle of the reward landscape was often incorrect. Thankfully, the extremities of the reward landscape were still generally quite accurate, so I was still able to use this reward function, but the results were always that the model's writing style was noticeably "off."
After a couple days of experimentation and several failed training runs, I was able to create a LoRA of Qwen3-14B that reliably passes ZeroGPT's classifier. The final version of this model had an average AI score of 6.8% on the actual ZeroGPT classifier. Out of 8,080 tested essays on the real classifier, 8,017 evaded detection, with only 63 being detected as AI-generated. However, due to the strict nature of the reward functions that I had to put in place to prevent reward hacking, the model's writing style is a bit stilted and reads strangely.
You can download the final checkpoint of the model here.
Expanding to Harder Classifiers: Pangram
Pangram is a new AI text classifier that claims near-perfect accuracy. They claim, in their technical report and on various pages on their website, that they get 99+% accuracy. Depending on the domain of the text being classified, they claim up to 99.9% accuracy. After years of hearing about how inaccurate AI text classifiers were, and after having tested ZeroGPT and found its accuracy very lacking, naturally, I was quite skeptical.
Imagine my surprise when it turns out Pangram wasn't lying!

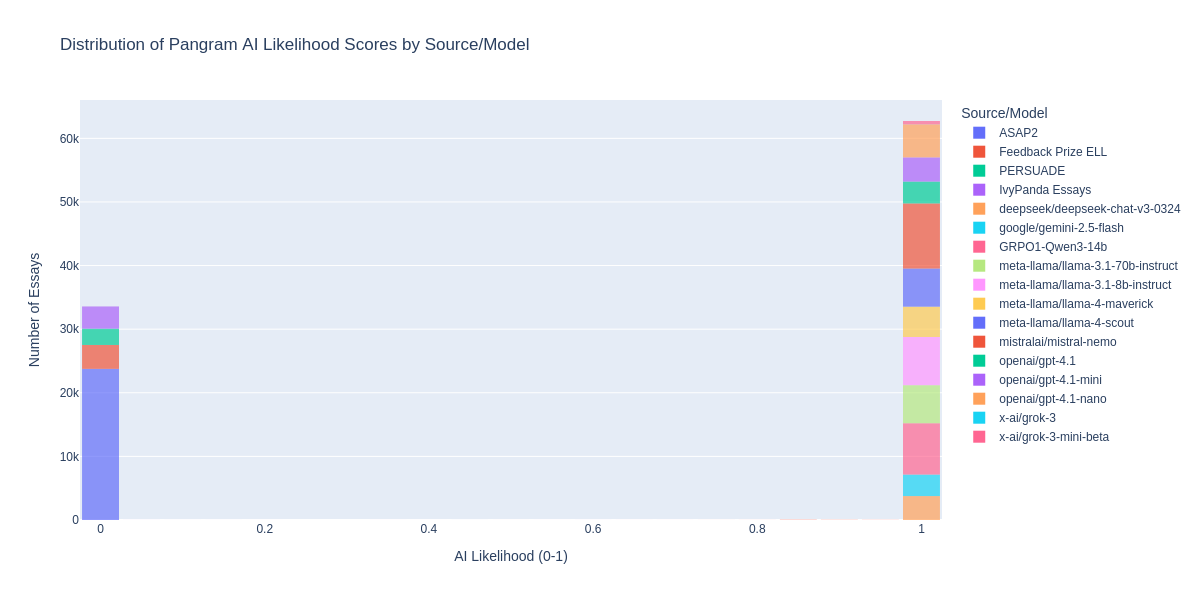
Testing the same dataset that I had used before against Pangram's API, I found their accuracy shockingly high. Out of 96,468 essays tested, Pangram correctly classified 96,457 of them. Of the 11 that were incorrectly classified, 10 were false negatives and 1 was a false positive. Overall, their accuracy was 99.98% accuracy. Wow! Accuracy on human-generated texts can be hand-waved away by the fact that the dataset of human-written essays I tested on is comprised of a couple public datasets filtered for quality, but accuracy on LLM-generated essays can't be, as I generated all of these essays myself.
Update: After speaking to Pangram staff, it turns out that my dataset of human essays has no overlap with their training data. ASAP2, Feedback Prize ELL, and PERSUADE aren’t licensed for commercial use, so they didn’t train on them. They also say they chose not to train on IvyPanda. Crazy!
As you can see in the above distribution of scores from the essays tested, their classifier's scores tend extremely hard towards the extremities of the score range. This behavior is quite different from ZeroGPT, which had a good range of scores in the middle. Pangram's very binary behavior posed two major challenges. First, because Pangram's classifier was clearly much more well-trained than ZeroGPT's, I knew that imitating the classifier's behavior would be much harder. Second, because the reward landscape had such a steep cliff, training directly on Pangram's API was not likely to yield good results; out of any set of generations in a GRPO training step, none of them were likely to perform notably better than any of the others, and so training would stall.
Regardless, I decided to try using Pangram's API as the reward function, just to see what would happen. My hunch was correct. The model (Llama 3.1 8b this time) didn't learn much at all. Maybe, had I let it run longer, it would've gained a foothold on how to correctly fool the API and started to climb in reward value, but after a couple dozen steps I saw no progress and didn't want to waste time and GPU rental money on pursuing this avenue further.
Next, I hypothesized that I might be able to use the ZeroGPT distilled classifier that I had already trained to gain a foothold on the reward landscape and start climbing. ZeroGPT is significantly less accurate than Pangram, and my classifier is even more inaccurate than ZeroGPT because it's just trying to mimic ZeroGPT's behavior, but I figured that, after all, these classifiers were all looking for the same set of recognizable yet hard to define behaviors in text. This hypothesis turned out to be correct.
After training for around 300 steps on the ZeroGPT distilled classifier, along with the other reward functions that just did basic sanity checks, I added Pangram's API as a reward function directly. During the first 300 steps, I chose not to have this reward function active, as I didn't want the occasional Pangram API error to cause the model's training to go off on a tangent. This worked! The training progressed and the model learned to write essays in a style that Pangram's API didn't detect.
To address the previous issues with writing quality in the Qwen training run, which were likely caused by my shoddy reward functions, I applied a new reward function based on GPT-4.1-nano's assessment of the quality of each essay. Each essay written was passed to GPT-4.1-nano and it was asked to reply either "GOOD" or "BAD" based on the quality of the writing. To create a usable reward landscape, the probabilities of "GOOD" and "BAD" were taken using the log probs of the model's output. This weak-to-strong generalization worked perfectly, and GPT-4.1-nano's assessment kept the model's writing style coherent during training against the Pangram API.

The final version of this model is exactly what I was hoping for. It writes coherently, follows instructions well, and evades detection about as well as I could hope for, given the quality of Pangram's classifier. In a test of 4,767 essays generated by Llama-3.1-8b-Pangram, 4,257 of them (89.3%) evaded detection, using 50% AI as the detection threshold. 2,766 of the essays scored "Fully human-written" in the classifier.
While I might've been able to push these evasion rates higher, at this point, I was satisfied with my experiment, and I'd already wasted enough money on GPU rentals for this project that I didn't want to spend a whole lot more.
Note: I want to clarify that I don't work for Pangram, I wasn't paid by Pangram, and I received nothing for my good review of Pangram's performance. In fact, I did all my testing totally unauthorized.
I've made the Pangram evasion model available here, but in this case I've gated access. Pangram's classifier is very good, and as I'll explore later, I don't think it's morally correct to freely make available something which will damage what I consider to be a high quality tool. If your HuggingFace account has activity on it that indicates you're interested in AI research, I'll approve access, but I'd prefer to limit the spread of this to avoid harming the company.
GPTZero
For my last little side quest, GPTZero (not the same company as ZeroGPT) was my next target, and turned out to be the hardest to test thoroughly but the easiest to pass of the entire group. I couldn't find a way to use their API without paying, and I wasn't about to pay them, but I was able to test a limited subset of generated essays in my browser. My hypothesis earlier about generalization seems to be correct: Llama-3.1-8b-Pangram generalized just about perfectly to GPTZero's classifier. I tested 15 essays and got 15 "mostly human" responses. I didn't see any reason to investigate this one much further than this.
Conclusion and Future Plans
I came into this project with the idea that AI text classifiers were totally inaccurate. I was wrong about that, but I'm still troubled by some of the practices in the AI text classification space. Pangram's classifier is a great example of this service being done right, but the problem to me is that all of the classifier services make claims about high accuracy that are misleading at best and outright lies at worst. The majority of these tools are not suitable for use in situations where false positives can cause real harm, like academic dishonesty investigations.
I didn't expect any of them to meet my idea of what's reasonable to deploy in practice, but I was pleasantly surprised to learn that this problem is (maybe) more solveable than I thought. However, I'm not sure how feasible services like this will be long term. I'm just one guy doing this as a fun toy project to learn more about RL training for LLMs, and I was able to create a model that evades detection by the best classifier on the market.
The total cost of my training runs (including the failed ones) was about $80. There's already a cottage industry that has sprung up of people selling AI text classifier evasion tools, and although I am doubtful of their efficacy (maybe I'll explore this in a future post) I think they're going to become as common or more common as the tools they're trying to evade.
The biggest problem I see with the AI text classification space is that interpretability is a requirement for these tools to be useful, but interpretability metrics are both not great in their current state, and are also useful as RL targets. The cat and mouse game has already started and will only get worse from here.
In the future, I plan to explore more adversarial training techniques against these classifiers, but I think I'm going to continue to be selective about what I release. Although I very much have a problem with services like ZeroGPT, I don't want to contribute to an arms race that will ultimately make detecting academic dishonesty harder.
This was an interesting read, thank you!